I have an existing dataframe df1 created from a spreadsheet. I created a new dataframe df2 via the ‘write an R script to get data’ feature. In the script to create df2, I refer to and extract data from df1. It worked on the first day I wrote it but now it fails with “Error : object ‘df1’ not found”. I can view and refresh df1. Is extracting data from another dataframe a incorrect way to approach this? Should I instead read the spreadsheet directly in the script to create df2?
Hi mikev,
referencing to another data frame from inside ‘Import by Writing R script’ is not supported currently. This is because Exploratory manages all the data dependency between data frames and branches and managing this part of the dependency is a bit more tricky than we originally wanted it to be. But having said that, we’ll support this in near future releases, so stay tuned.
Thanks,
Kan
So it worked initially when I first wrote the script but refreshing or stopping and restarting exploratory caused the link to the dataframe to get lost?
Is the right approach to read the data in from the spreadsheet as part of the R script? I tried doing that using xlsx. First I was working on my windows machine and I had failures when I tried to install xlsx, are there issues with using it inside exploratory? After installing it by running exploratory as the admin user I still wasn’t able to access xlsx inside the R script.
I’d like to avoid using readxl because my spreadsheet has duplicate column names. If I can’t get xlsx working I’ll write the code to fix the duplicate column names either before or after reading it in.
Not sure why it even worked initially. In my environment, it doesn’t work from the beginning. It could be a bug. We’ll look into it further when supporting the data frame reference from the R script data.
As to ‘xlsx’ package, seems it’s depending on Java, so that might be contributing to the issue, though I’m not 100%.
As to the duplicated column names, I just tested it and confirmed that they are imported ok by renaming the column name automatically.

You can rename the column names later by either using ‘rename’ command or have your own custom R function which takes care of the rename for all the columns you want, and call it from the command line with ‘Command’ button.
Yes, the column renaming works when I create a regular dataframe. My problem is that in my R script to import the data frame I use readxl and it complains about the duplicate column names. I’m doing this because I can’t read the dataframe because of the limit we’ve been discussing and I have messy transforms I need to do to the spreadsheet data to create the data frame. I was hoping to use xlsx instead of readxl to avoid the need to fix the column names in my code. I’ll try doing the work to read the data without it being treated as a header, rename the columns (I’ll be doing what exploratory does when it reads the spreadsheet). Thanks for the quick responses and guidance.
I’ve recently switched to a mac and installing R packages isn’t working. I don’t get the drop-down list of packages when I type in the User Packages field. When I type any name of a package and press the Install button I get the following message. We don’t have a proxy. Other things, like R-Studio, can get to cran without problems.
Installing package into ‘/Users/Mike.Vogelmike1230/.exploratory/R/3.3’
(as ‘lib’ is unspecified)
Warning: unable to access index for repository http://cran.us.r-project.org/src/contrib:
cannot open URL ‘http://cran.us.r-project.org/src/contrib/PACKAGES’
Warning: unable to access index for repository http://cran.us.r-project.org/bin/macosx/mavericks/contrib/3.3:
cannot open URL ‘http://cran.us.r-project.org/bin/macosx/mavericks/contrib/3.3/PACKAGES’
Warning message:
package ‘compare’ is not available (for R version 3.3.2)
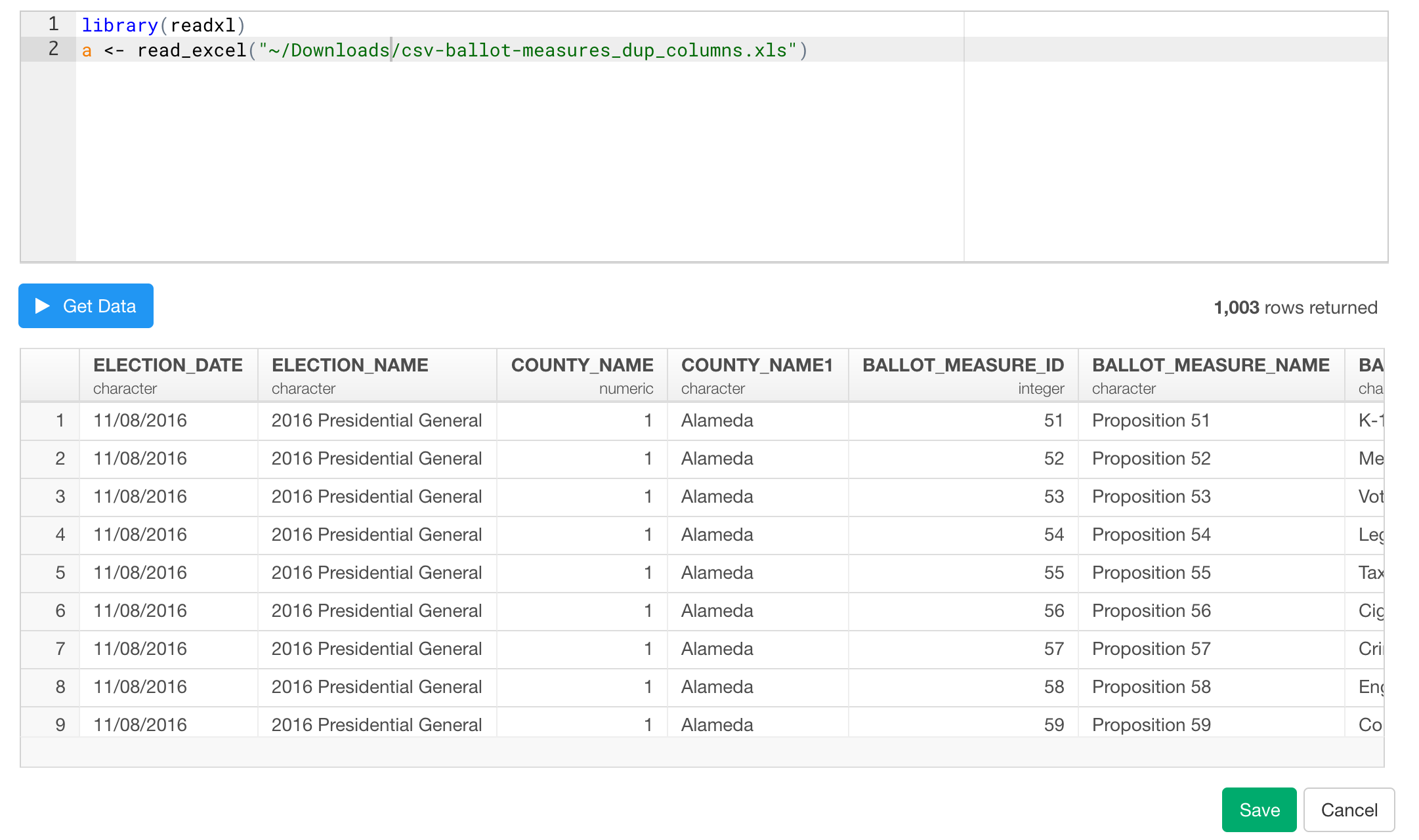
It’s taking care of the duplicated column names with directly calling ‘read_excel’ function here. Would it be possible to send me the sample file that includes only the column header and the 1st row (this can be dummy) so that I can try it out here?
I’m separating the R package install issue as a different topic to track.
HI Kan,
is this feature now supported in 4.3 version…or there is any other way to reference another column from different dataframe.
You can always reference a column in a different data frame by using
<data_frame_name>$<column_name>
format.