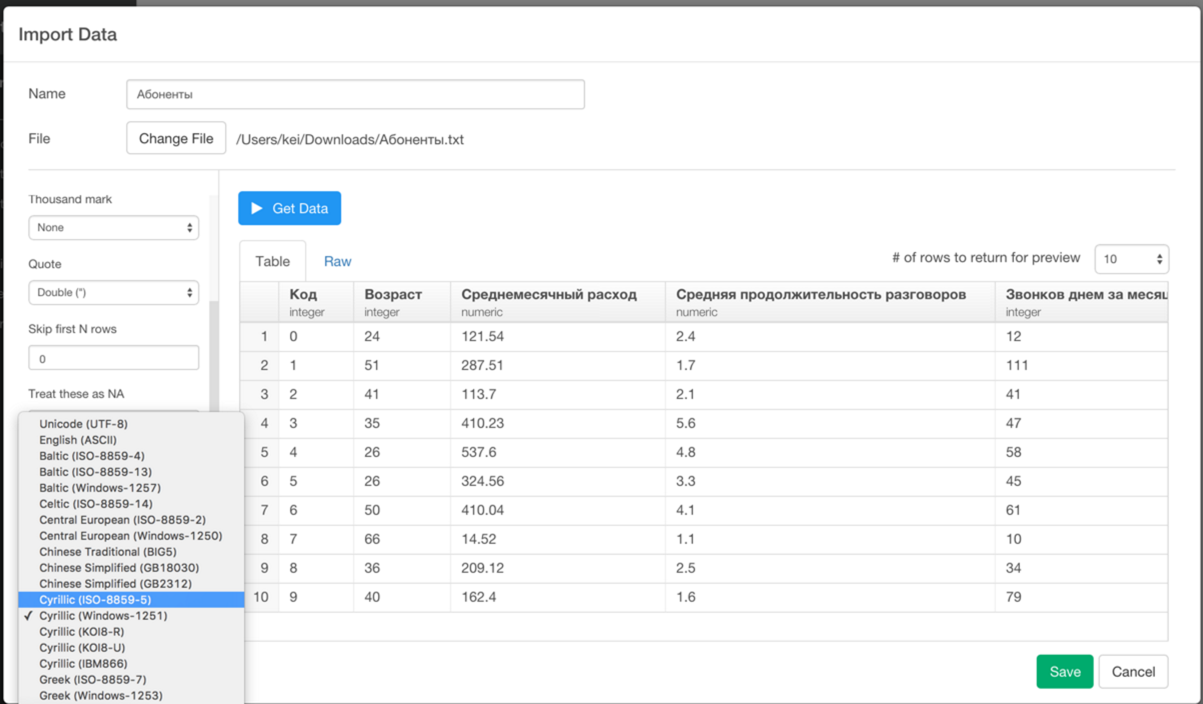
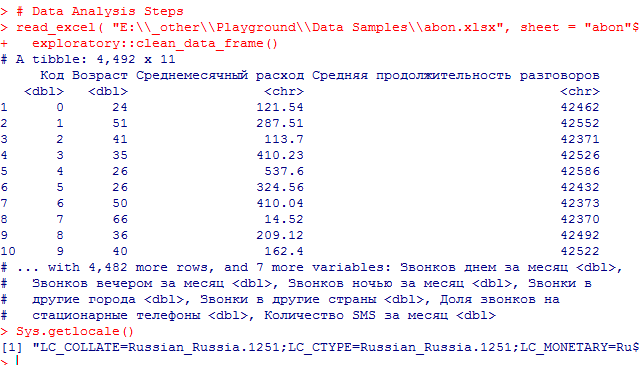
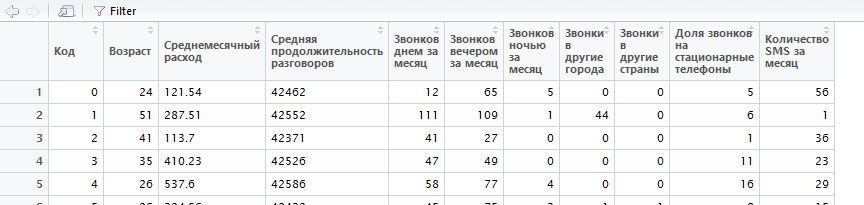
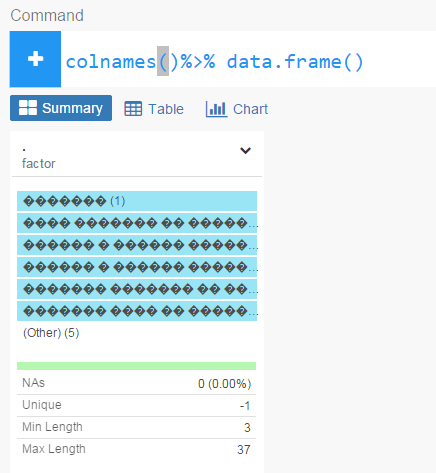
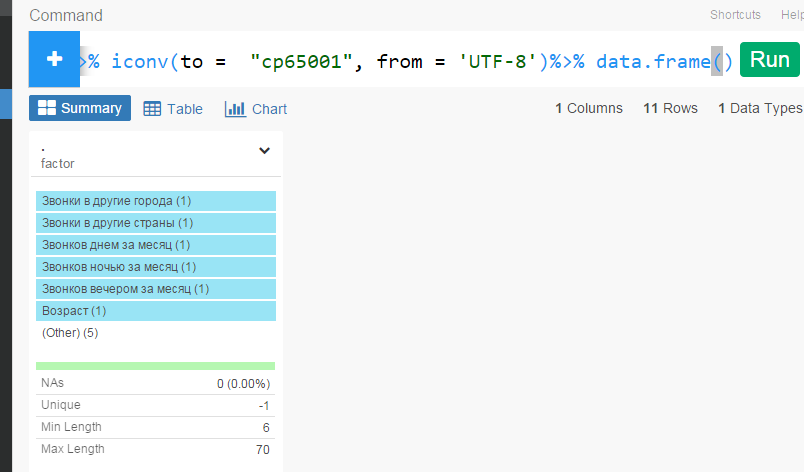
Exploratory Interaface does not show Russian(cyrillic characters):
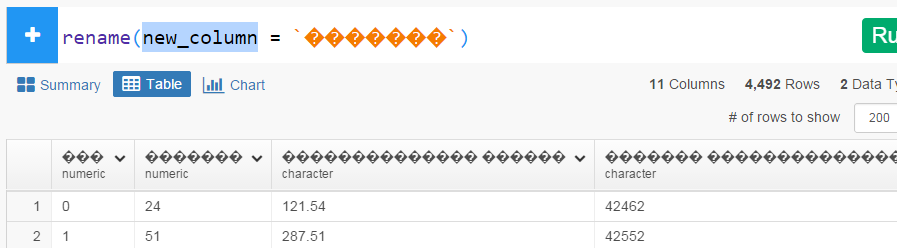
- both in headers and in columns
- in summary view, in table view, in command editor
Exploratory script works fine in RStudio, R with the same locale settings
R studio dataviewer shows names of the columns just fine
Dataframe was loaded from Excel file;
But the same problem remains when dataframe was loaded from csv via script with correct encoding (“WINDOWS-1251”)
read_delim("E:\\_other\\Playground\\Data Samples\\abon.txt" , "\t", quote = "\"", skip = 0 , col_names = TRUE , na = c("","NA"), n_max=-1 , locale=locale(encoding = "WINDOWS-1251", decimal_mark = ".") , progress = FALSE)
When you export data via “save as csv”, the file is saved in UTF-8 with correct headers and content.
After csv reimport with “UTF-8” encoding - the same problem in the intarface.
So it looks like the problem is mainly related to interface, not to R or its settings.
In Mac version the same problem do exist.
Another problem - cyrillic names does not work for import dialog in Windows version:
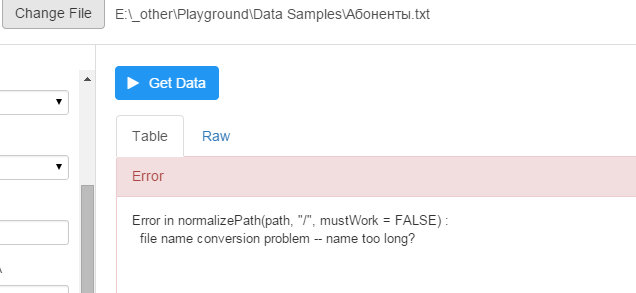
as well as for custom script import:
#Data Analysis Steps
xx <- read_delim("E:\\_other\\Playground\\Data Samples\\Абоненты.txt" , "\t", quote = "\"", skip = 0 , col_names = TRUE , na = c("","NA"), n_max=-1 , locale=locale(encoding = "WINDOWS-1251", decimal_mark = ".") , progress = FALSE) %>%
exploratory::clean_data_frame()
while the same script works fine for Rstudio.
For Mac version import from files with cyrillic characters works fine.
“R version 3.3.1 (2016-06-21)”,
“Platform: x86_64-w64-mingw32/x64 (64-bit)”,
“Running under: Windows 7 x64 (build 7601) Service Pack 1”,
“”,
“locale:”,
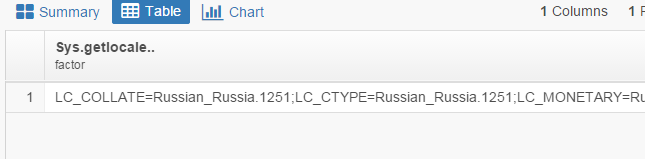
"[1] LC_COLLATE=Russian_Russia.1251 LC_CTYPE=Russian_Russia.1251 ",
"[3] LC_MONETARY=Russian_Russia.1251 LC_NUMERIC=C ",
"[5] LC_TIME=Russian_Russia.1251 ",