Symptom
Currently, there is an limitation that built-in Twitter data source only returns last 10 days data even if you set more than 10 for Last N Days parameter.
Workaround
There is a workaround to use rtweet to get more data from Twitter.
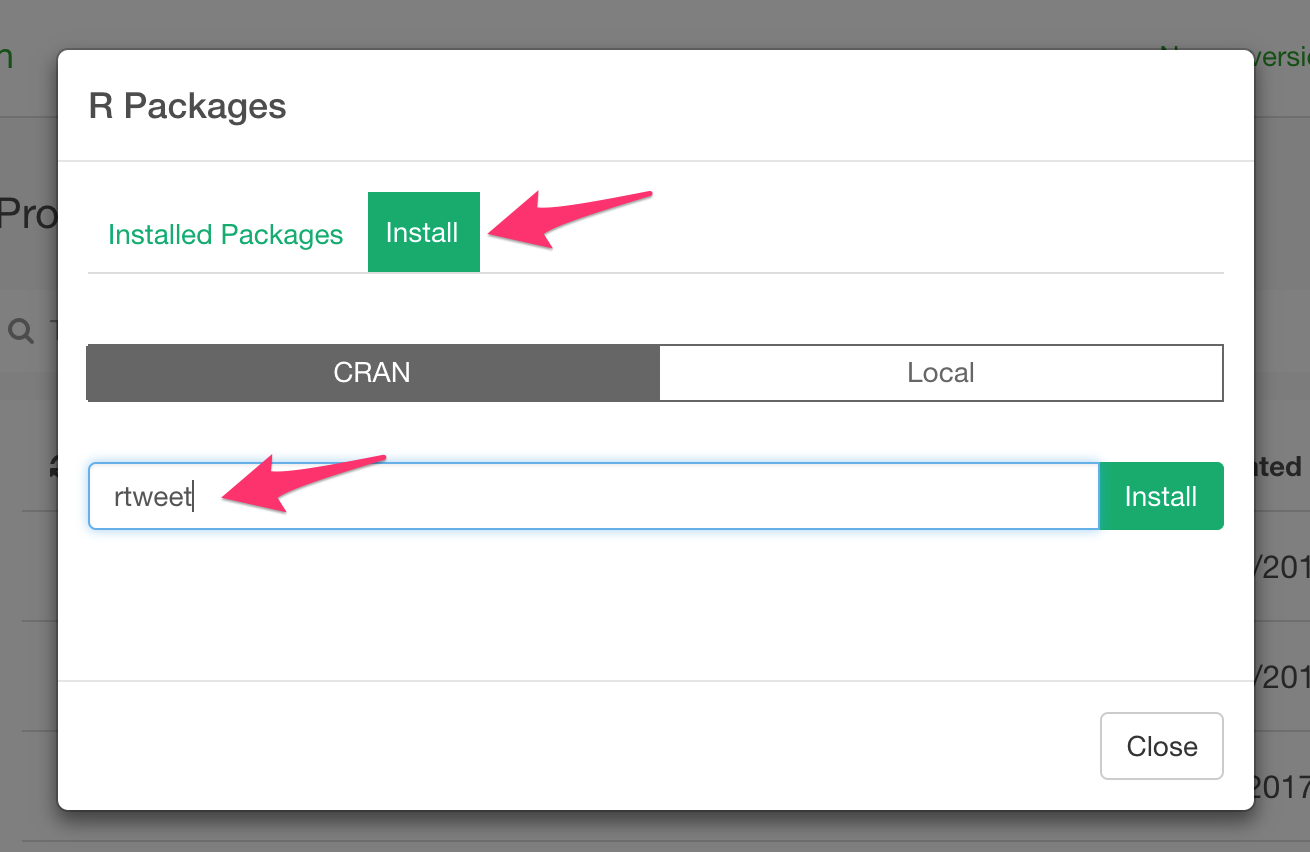
Install rtweet
And install rtweet from here.
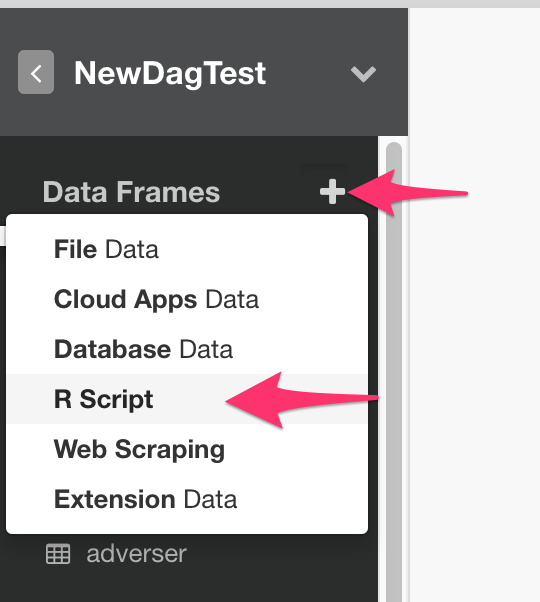
R Script Data Source
Then create a data frame with R Script like below.
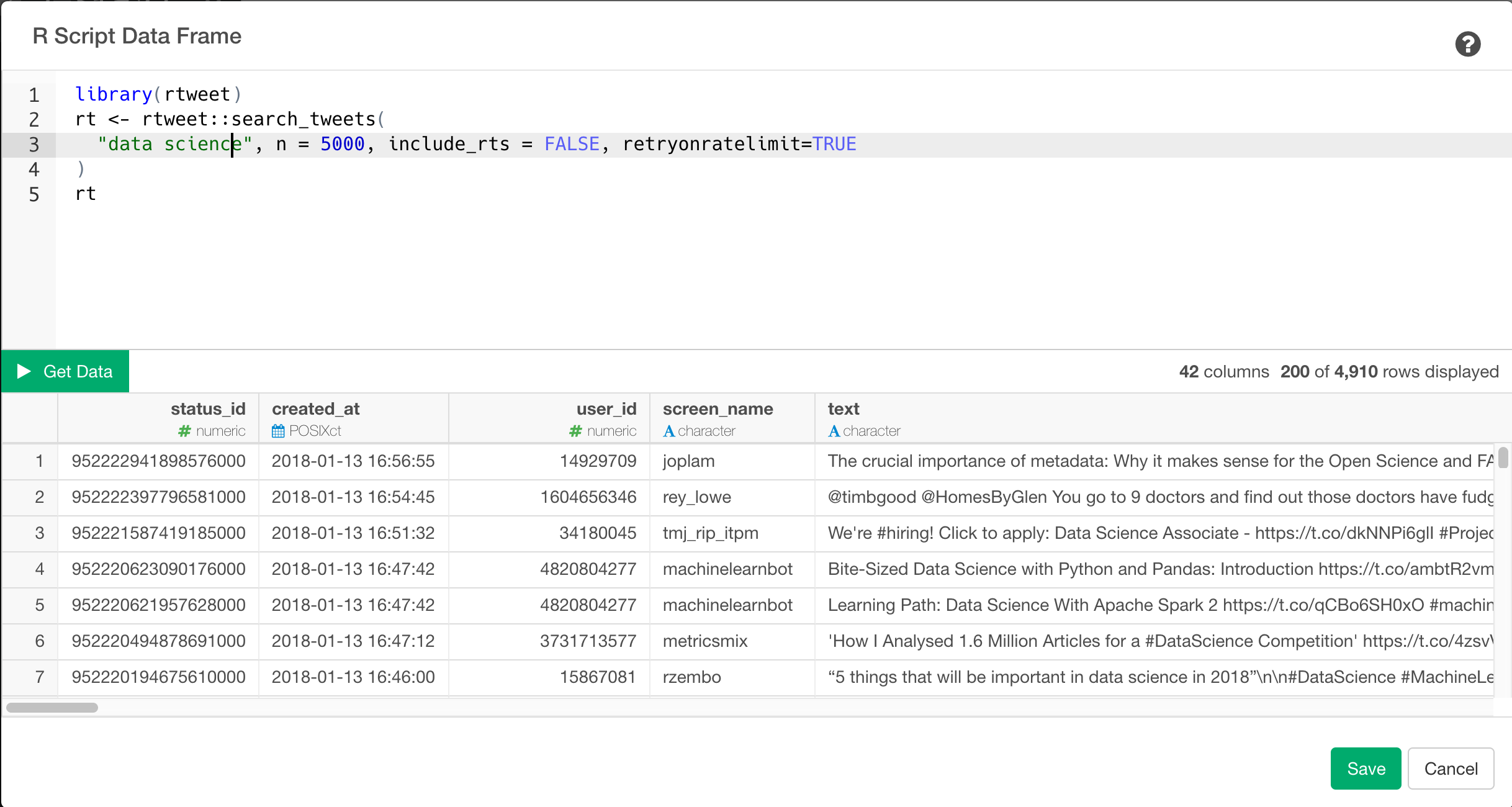
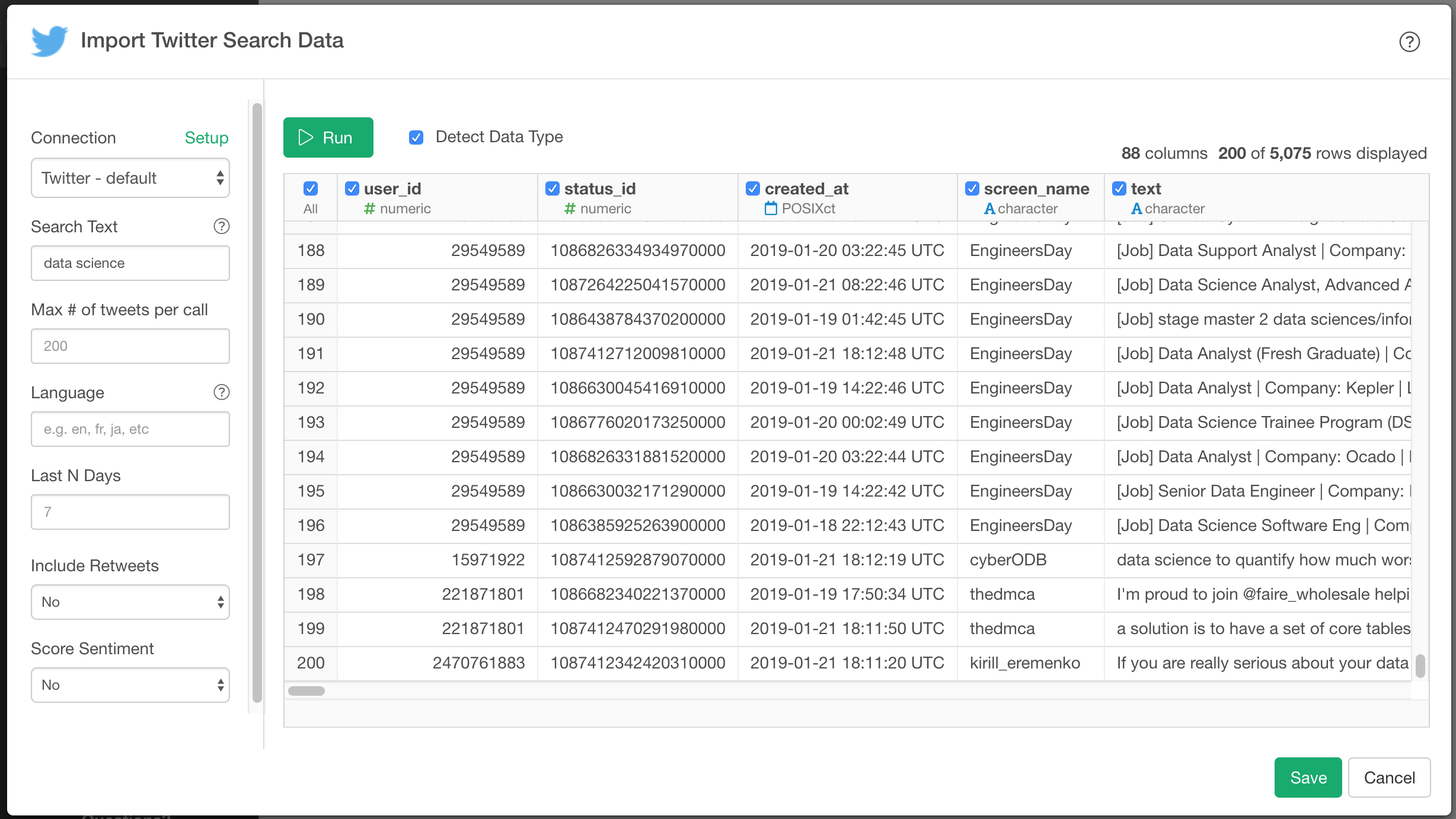
Then write R Script something like this. Below is an example that gets data with search keyword “data science” and upto 5000 tweets.
library(rtweet)
rt <- rtweet::search_tweets(
"data science", n = 5000, include_rts = FALSE, retryonratelimit=TRUE
)
rt
This will give you more data from twitter
Hi,
Is there still a limitation when extracting twitter data using Exploratory’s Cloud Apps Data Sources? I just tried to extract the last 7 days using Twitter search and only get data for the past 24 hours.
Thanks,
Gustavo
Hi Gustavo,
Could you try it with latest Exploratory (version 5)?
Now we switched to use rtweet for built in Twitter Data Source
And this should give you as many tweets as the API can fetch within limitation that Twitter imposes.
Hi Hide,
Thanks for responding. Yes, I’m using the latest Exploratory version (v.5.0.1.0). It is unclear to me how Twitter decides what gets fetch back to me I refresh my API connection but the total counts of tweets vary greatly each time. For instance, I could get up to 12,000 rows when refreshing my connection and other times I get 3,000. I tested this a couple of times within a two-day span. I also never get more than 24-hours worth of data for this particular connection even though I set it up to go back and pull 7-days.
I came across this article as I’m trying to understand the differences in numbers. This is my first time looking at this type of data so very possible I just don’t know how twitter data really works. I just wanted to make sure it is not an issue on how I’m setting up Exploratory.
I have the same problem here, tried the latest version, but still only show past few hours tweets.
I also tried to install rtweet but the system doesn’t allow me to ‘update core package: rtweet’
Any suggestion would be greatly appreciated.
Hi Gustavo and Junxiong
There is no other setup required. Exploratory is simply throwing a query against Twitter with your search keyword and Twitter returns results based on your Twitter account status (standard, premium or enterprise). So we get what Twitter returned. What we can do here is use supported filter condition by Twitter.
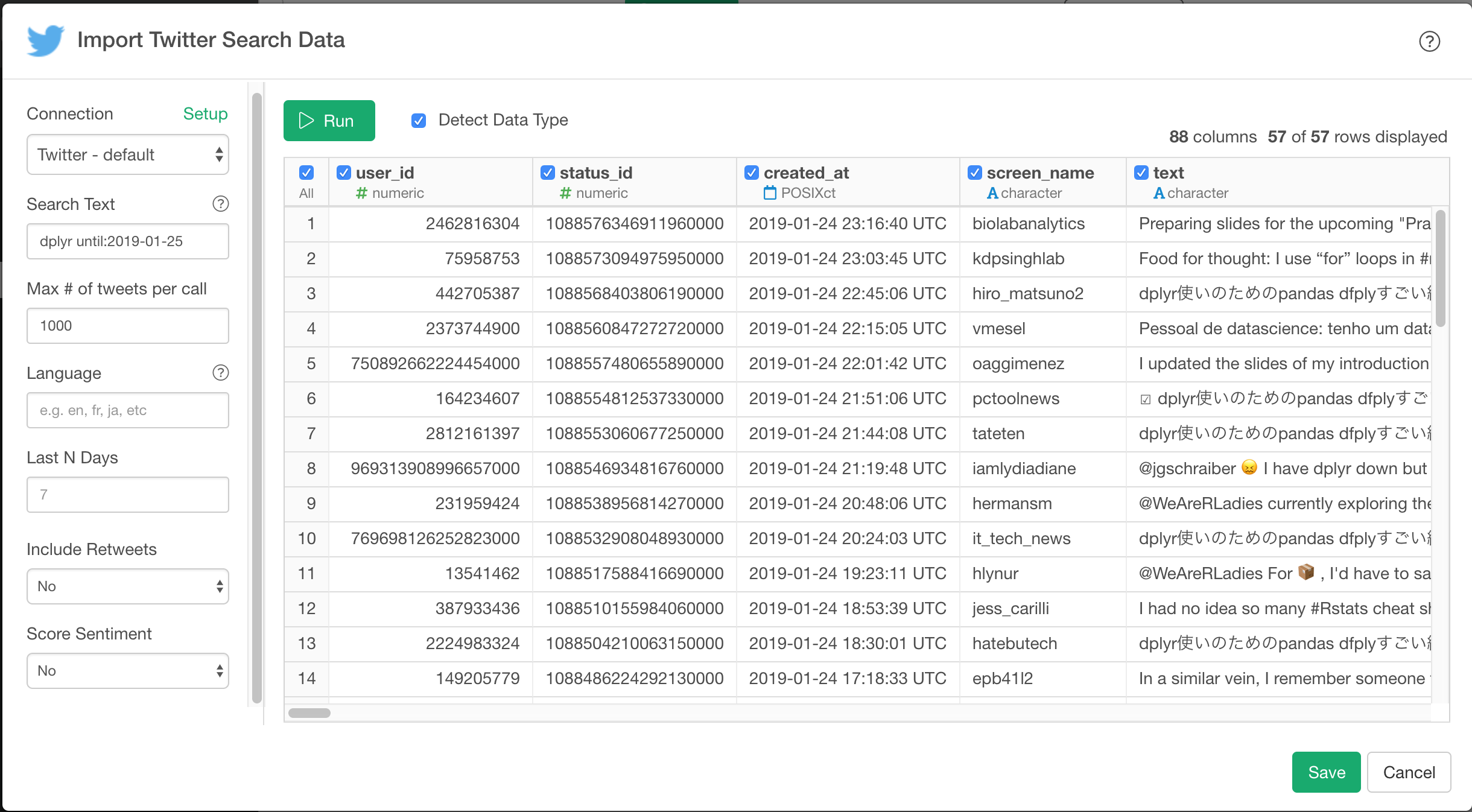
For example, If you need older tweets, you can use the until condition like below.
if you want to get tweets related to dplyr until 2019-01-25
You can query it by dplyr unit:2019-01-25 as a Search Text.
you can also use since condition so if you want to get tweets between some time range, you can do as follows:
dplyr since:2019-01-27 until:2019-01-30
Again, one thing we need to be aware of is that if your Twitter Account is “standard” there is some limitation (which is imposed by Twitter)
https://developer.twitter.com/en/docs/tweets/search/overview/standard
The Twitter’s standard search API (search/tweets) allows simple queries against the indices of recent or popular Tweets and behaves similarly to, but not exactly like the Search UI feature available in Twitter mobile or web clients. The Twitter Search API searches against a sampling of recent Tweets published in the past 7 days.
Before digging in, it’s important to know that the standard search API is focused on relevance and not completeness. This means that some Tweets and users may be missing from search results. If you want to match for completeness you should consider the premium or enterprise search APIs.
Thank you Hide, I will give it a try later.
Thanks Hide! Your response is very helpful. I guess I need to come to grow comfortable with the term relevance vs. completeness. Here are a couple of additional links for Twitter premium accounts that someone may find helpful https://goo.gl/jR9Khu and https://goo.gl/6ZrzeJ.