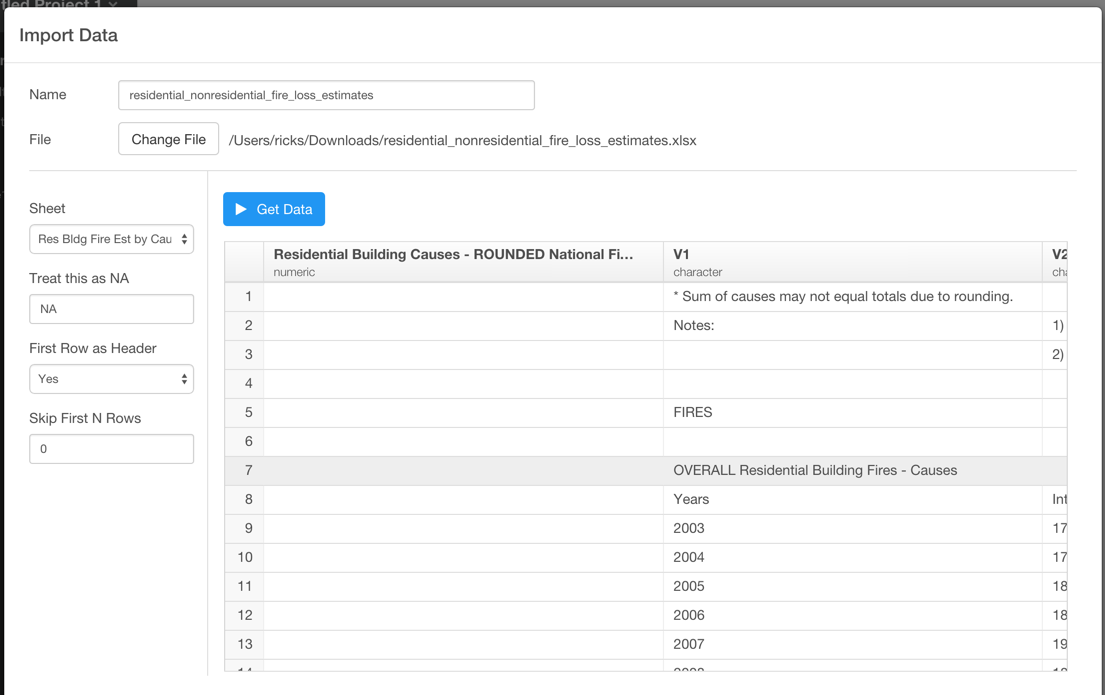
I downloaded an excel file and I’m trying to import a table data from one of sheets in that file. The problem is, there are a couple of other tables in the same sheet. How can I import one that I want?
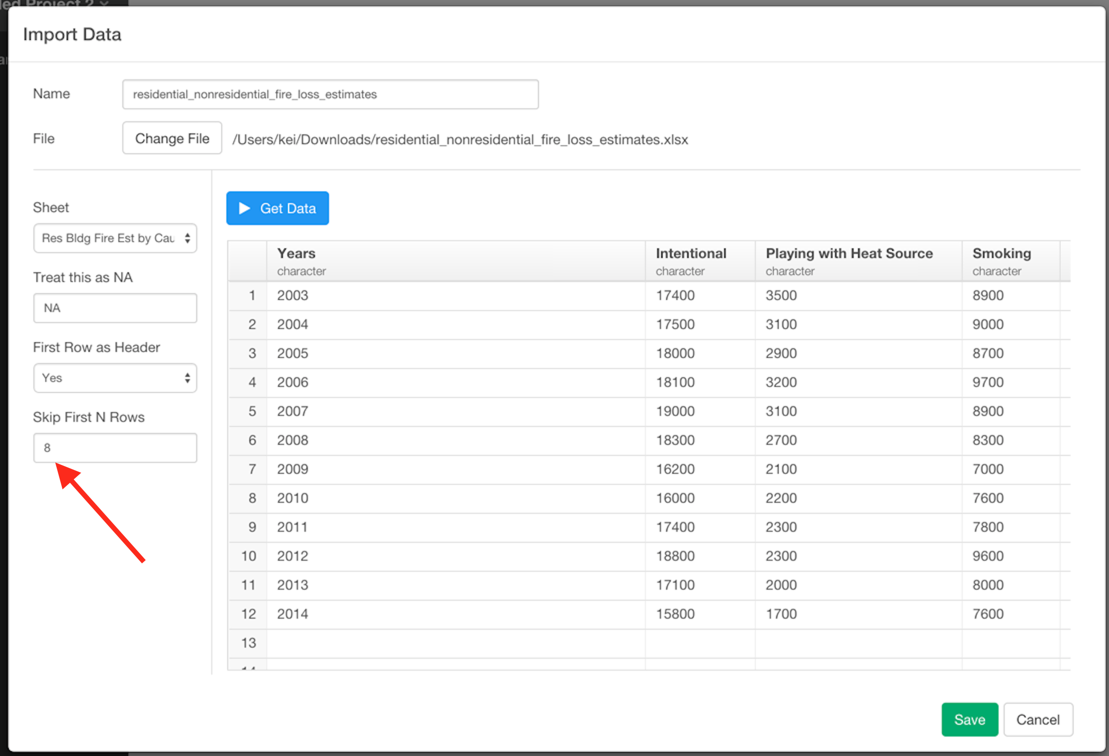
1). At the import dialog, set skip first N rows and click ‘Get Data’ again. Then you see a better data view like this. If you scroll down, you still see other tables that you don’t want. But here just go ahead and click “Save”.
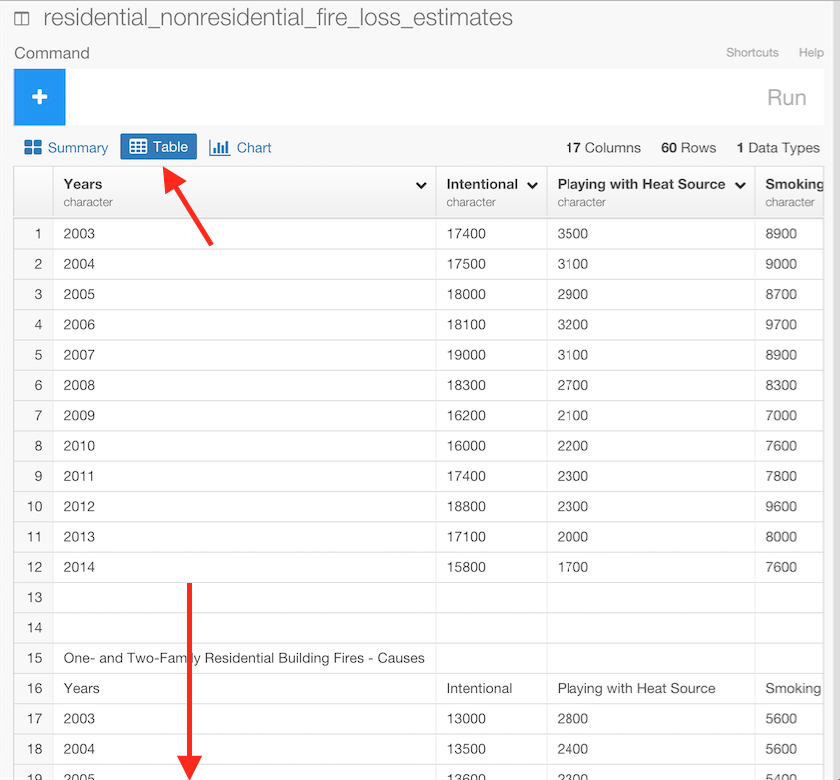
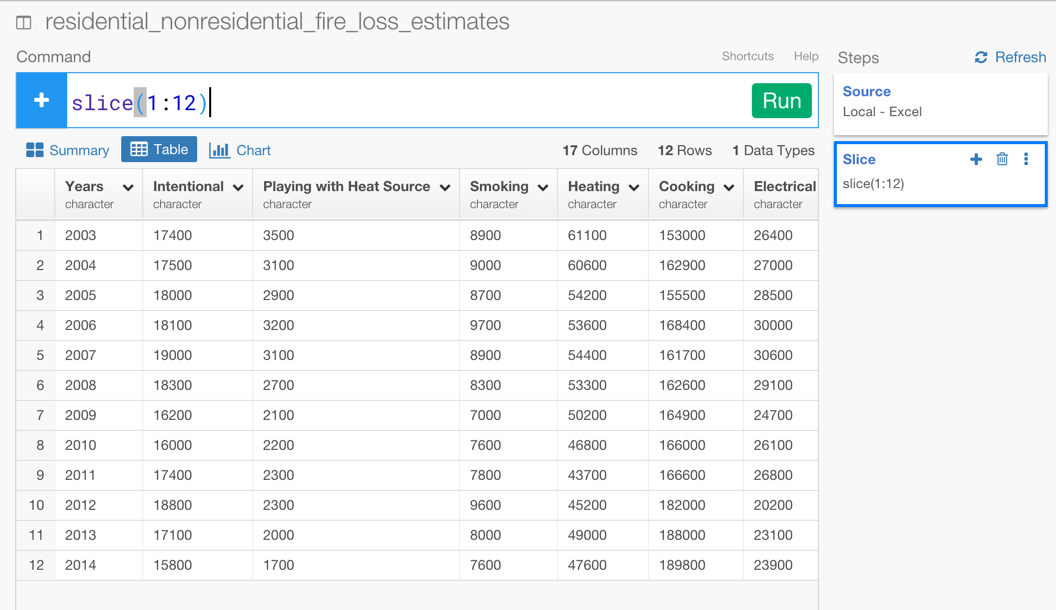
3). If you look at the data, you can easily see you just need first 12 rows. You can use slice command to crop only first 12 rows. Type slice(1:12) at the command box and click ‘Run’, then you see what you want.
As a follow-up, is there a way to automate importing the first table from multiple spreadsheets (each with multiple tables) where the number of rows is inconsistent, but there is always a blank row between tables?