This post explains how to create a network of feature co-occurrences
ref: https://quanteda.io/reference/textplot_network.html
Import Twitter Data
As a first step, import Twitter data

If you save the data as Twitter_Search_1, this name is required in the next step so make sure to note it down.
and “text” is the column that contains words for the network of feature co-occurrences.
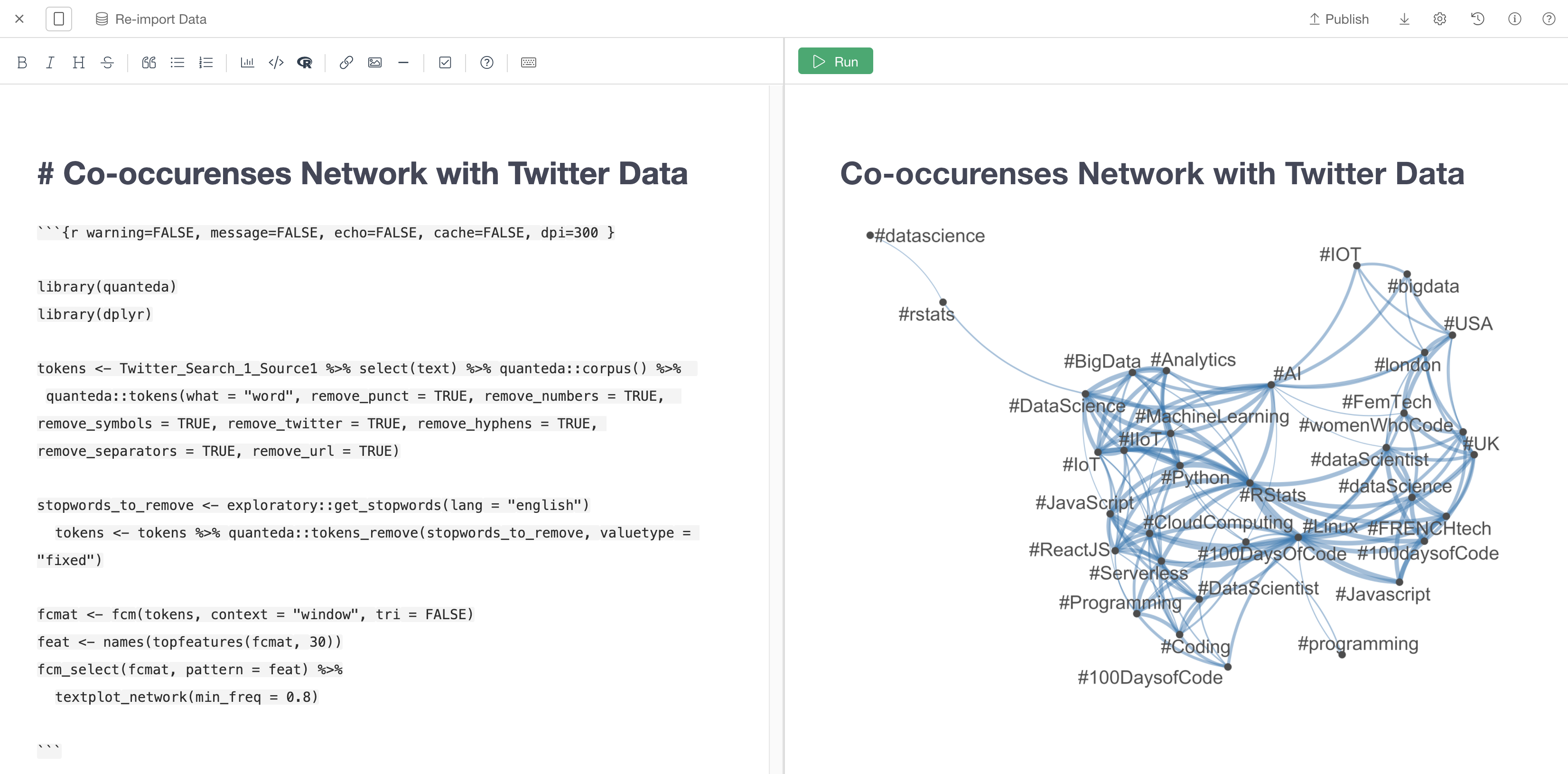
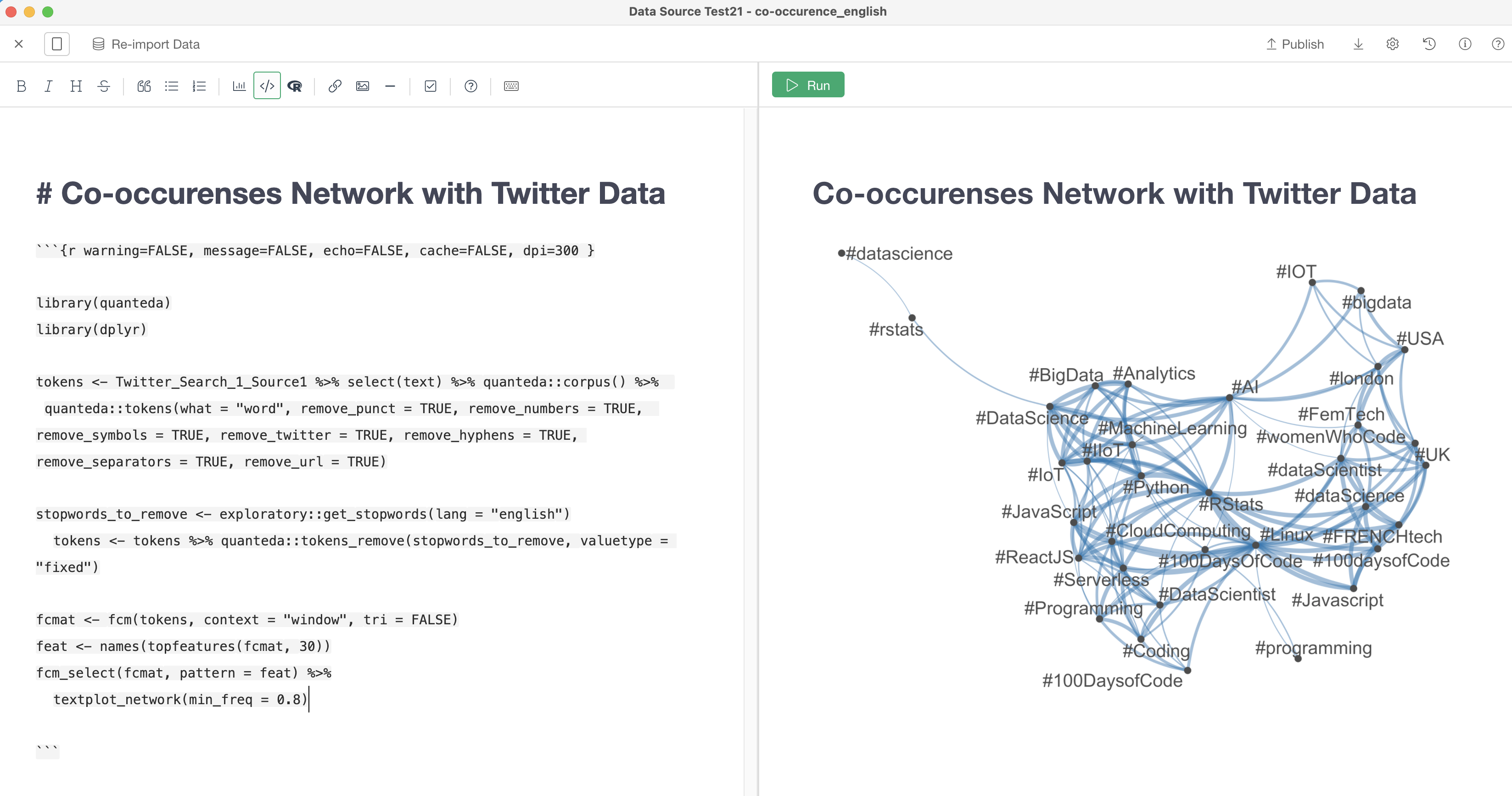
Create a Note
Create a note and paste the below script inside an R code block.
Make sure you type <Your_dataframe_name>_Source1 (my case Twitter_Search_1_Source1) for your data source in the script.
library(quanteda)
library(dplyr)
tokens <- Twitter_Search_1_Source1 %>% select(text) %>% quanteda::corpus() %>%
quanteda::tokens(what = "word", remove_punct = TRUE, remove_numbers = TRUE, remove_symbols = TRUE, remove_twitter = TRUE, remove_hyphens = TRUE, remove_separators = TRUE, remove_url = TRUE)
stopwords_to_remove <- exploratory::get_stopwords(lang = "english")
tokens <- tokens %>% quanteda::tokens_remove(stopwords_to_remove, valuetype = "fixed")
fcmat <- fcm(tokens, context = "window", tri = FALSE)
feat <- names(topfeatures(fcmat, 30))
fcm_select(fcmat, pattern = feat) %>%
textplot_network(min_freq = 0.8)

Click Run Button, and you can see a network plot like below.