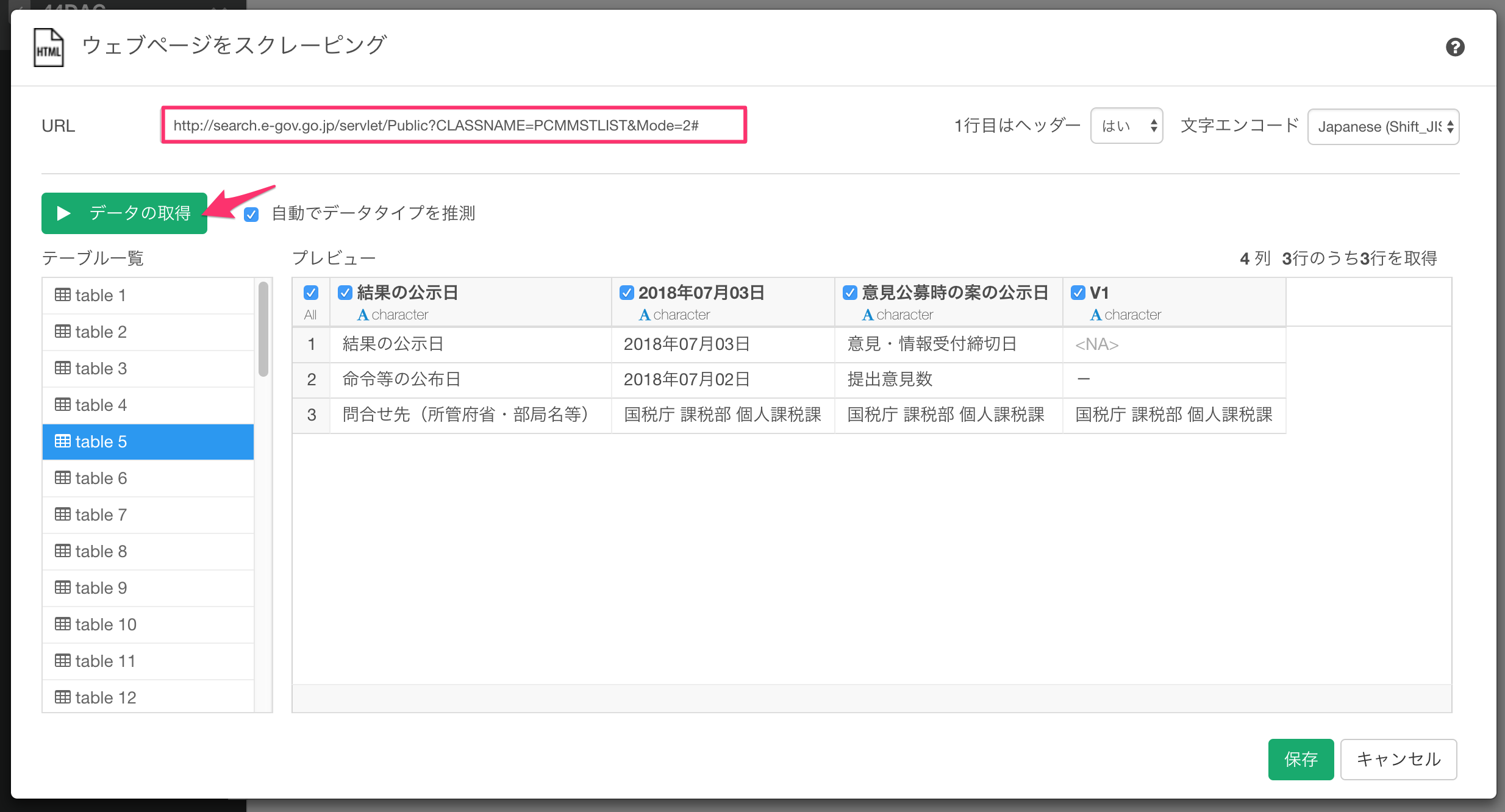
http://search.e-gov.go.jp/servlet/Public?CLASSNAME=PCMMSTLIST&Mode=2#
こちらのwebサイトをスクレイピングする際に、
2年ほど前に実行したスクリプトを実行すると
Error : is.data.frame(x) is not TRUE
というエラーがでて、実行されません。
Rの知識がまったくないため、どなたかお力をお貸しいただけると嬉しいです。
以下が実行したスクリプトです。
sample_2_pages.func <- function(){
loadNamespace(“httr”)
loadNamespace(“rvest”)
loadNamespace(“dplyr”)
res_list <- lapply(seq(4), function(i){
httr::GET(“http://search.e-gov.go.jp/servlet/Public”, query=list(CLASSNAME=“PCMMSTLIST”, Mode=2, Page=i-1))
})
tables <- lapply(res_list, function(res){
main <- rvest::html_node(httr::content(res, encoding = “Shift_JIS”), “#main”)
children <- rvest::html_children(main)
result_list <- list()
current_tag <- “”
for(child in children){
tag <- rvest::html_tag(child)
if(tag == “h2”){
current_tag <- rvest::html_text(child)
} else if (tag==“table”){
caption <- rvest::html_text(rvest::html_node(child, “caption”))
table <- rvest::html_table(child, fill = TRUE)
result_list[[length(result_list)+1]] <- dplyr::mutate(table, label=current_tag, caption=caption)
}
}
do.call(rbind, result_list)
})
do.call(rbind, tables)
}
Set libPaths.
.libPaths("/Users/username/.exploratory/R/3.3")
Load required packages.
library(rvest)
library(janitor)
library(lubridate)
library(hms)
library(tidyr)
library(urltools)
library(stringr)
library(broom)
library(RcppRoll)
library(tibble)
library(dplyr)
library(exploratory)
Data Analysis Steps
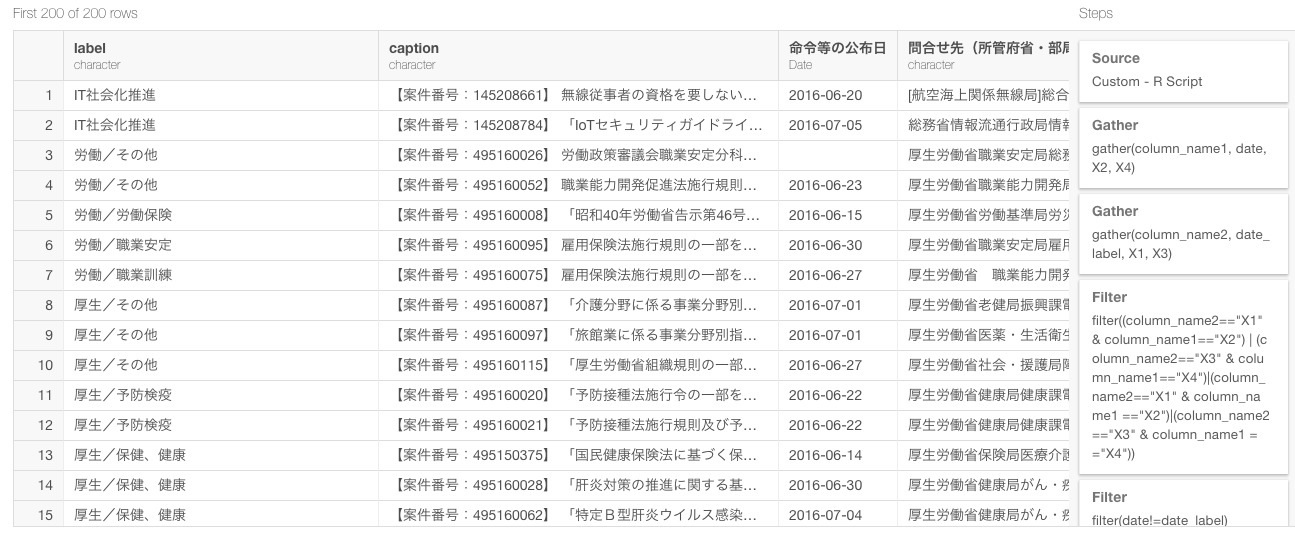
sample_2_pages.func() %>%
exploratory::clean_data_frame() %>%
gather(column_name1, date, X2, X4) %>%
gather(column_name2, date_label, X1, X3) %>%
filter((column_name2==“X1” & column_name1==“X2”) | (column_name2==“X3” & column_name1==“X4”)|(column_name2==“X1” & column_name1 ==“X2”)|(column_name2==“X3” & column_name1 ==“X4”)) %>%
filter(date!=date_label) %>%
distinct(label, caption, date_label,.keep_all=TRUE) %>%
select(-column_name1, -column_name2) %>%
spread(date_label, date) %>%
mutate(命令等の公布日 = ymd(命令等の公布日) ) %>%
mutate(意見・情報受付締切日 = ymd(意見・情報受付締切日)) %>%
mutate(意見公募時の案の公示日 = ymd(意見公募時の案の公示日)) %>%
mutate(結果の公示日 = ymd(結果の公示日)) %>%
mutate(caption = str_clean(caption)) %>%
mutate(提出意見数 = extract_numeric(提出意見数))