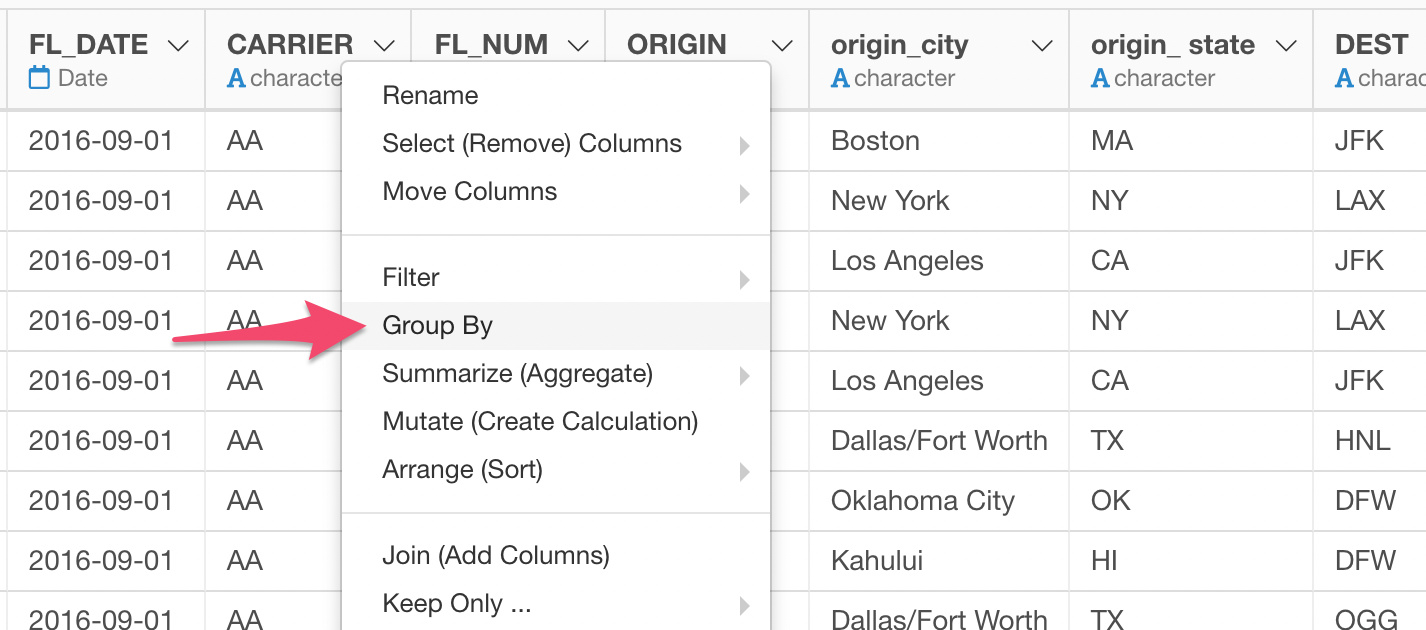
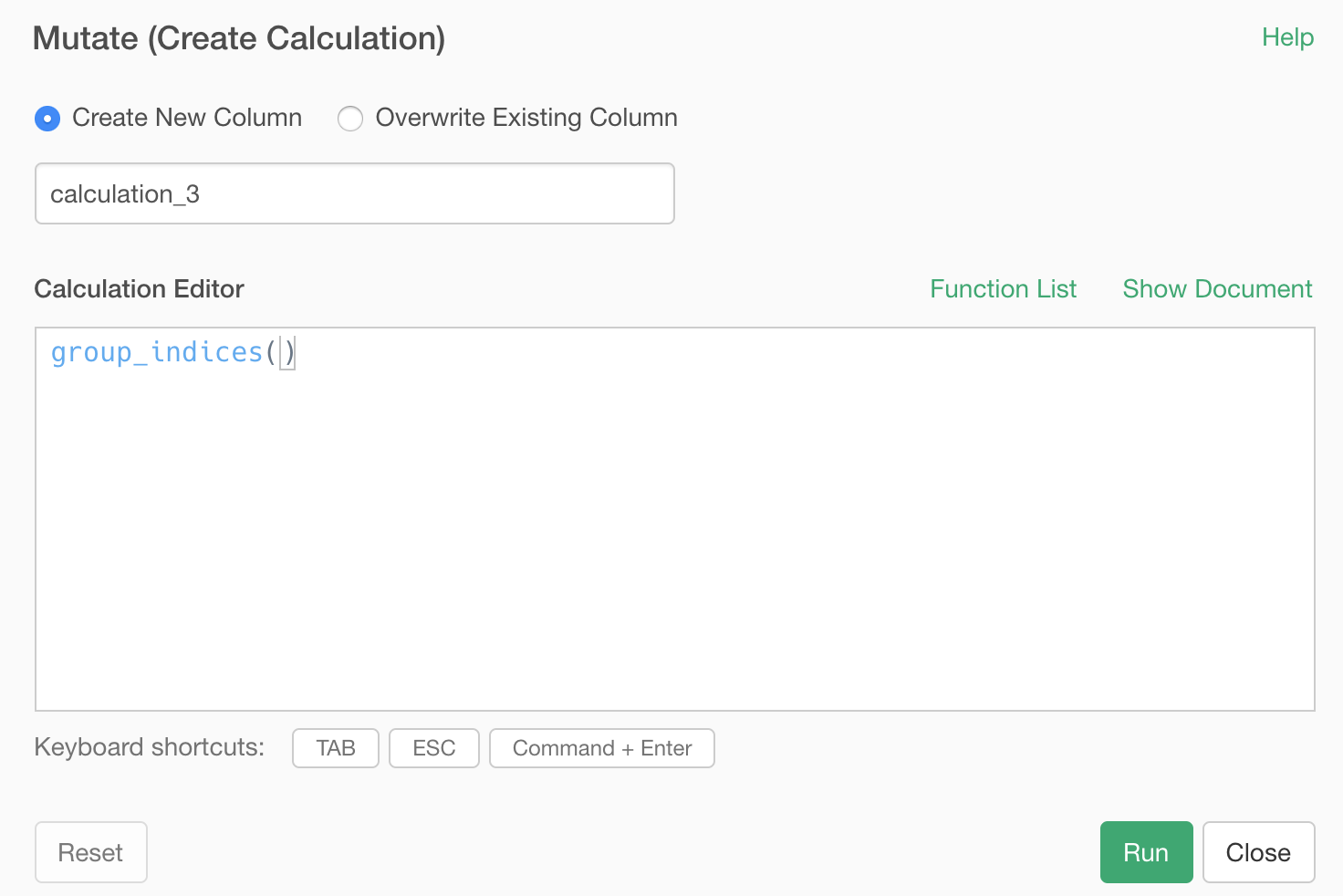
Here’s a question from our user.
I have a list of 50,000 physicians that are not labeled by what year they are in training. The physicians are listed in consecutive order by a numerical userid number.
Current Data:
Name Userid number City/State
Physician Name A - 1 - New York, NY
Physician Name B - 2 - New York, NY
Physician Name C - 3 - Washington, DC
To break out by the groups I need people who have consecutive doctor id numbers and have the same city state.
Desired Output:
Name Userid number City/State Group
Physician Name A - 1 - New York, NY Group x (First person)
Physician Name B - 2 - New York, NY Group x (Userid is plus one more than the last and same city with New York, NY)
Physician Name C - 3 - Washington, DC Group y (Userid is plus one more than the last BUT not the same city as New York, NY)