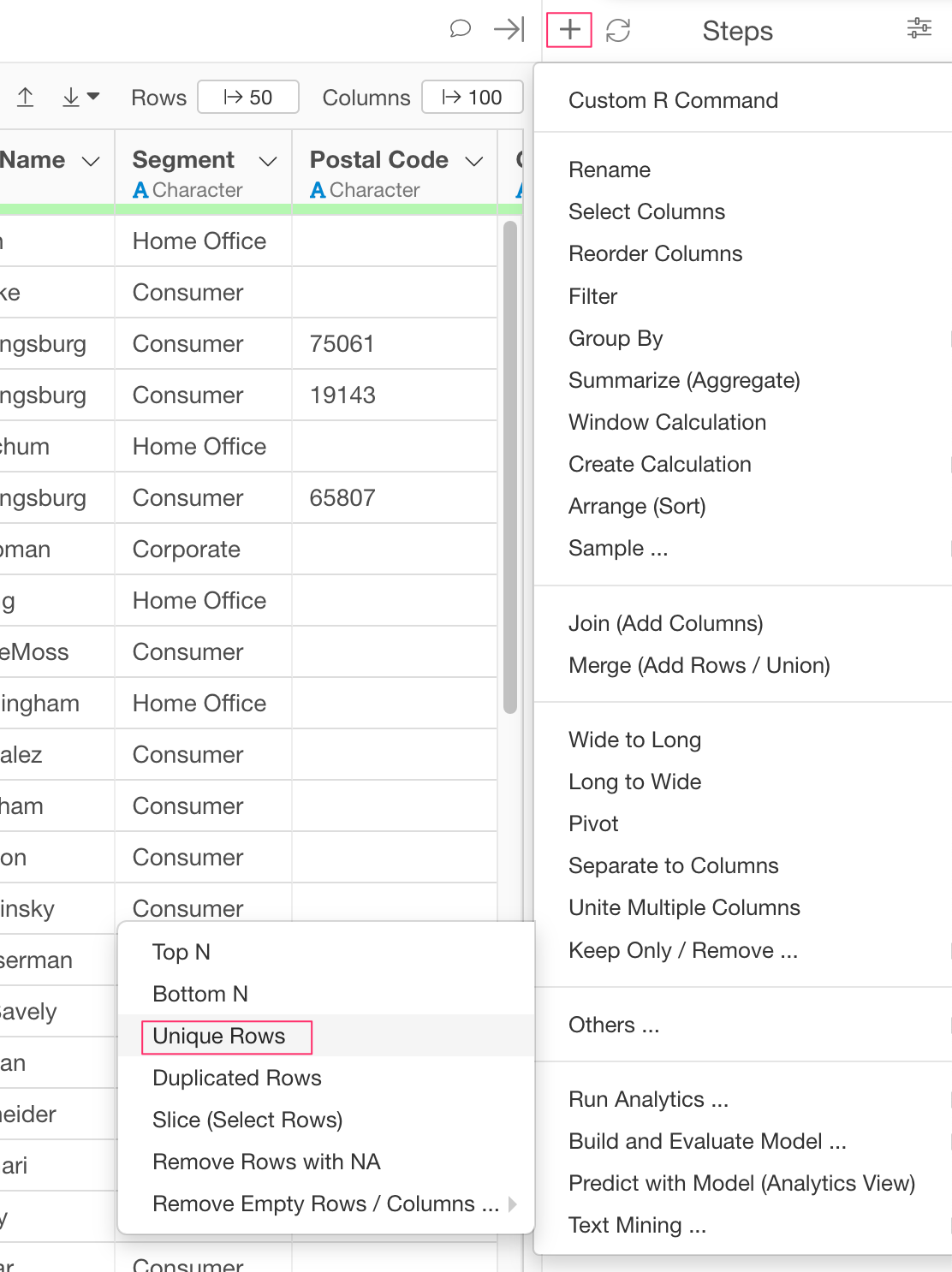
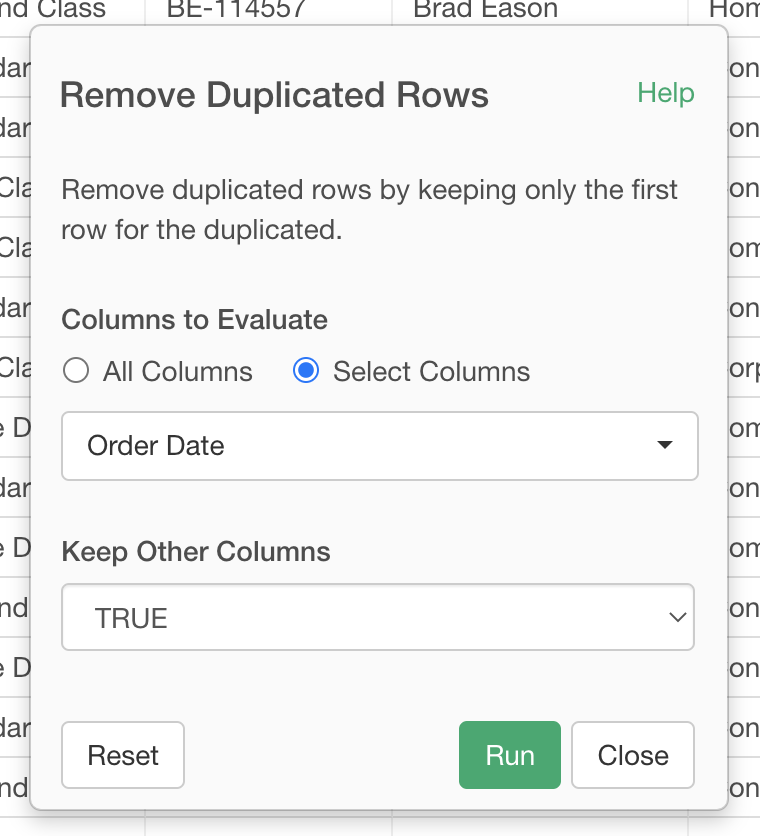
I’m working on a data that has many duplicate rows. How can I remove those duplicate rows?
Hi,
One way to remove duplicate rows would be “distinct” function.
distinct(COLUMN_NAME) gives unique set of the column value, removing the duplicate.
But by default, distinct function also drops other columns than the one you specified, but I would guess you just want to remove duplicate rows and keep columns.
In that case, distinct(COLUMN_NAME, .keep_all=TRUE) would keep the column values too. (The column values kept will be the the ones from the row that appears the first in the original data frame.)
Here, I created an example with “iris” data frame. (The rows with same “Species” there are not really duplicate rows, but I think this shows the idea.)
https://exploratory.io/data/hideaki/de097202a844
4 Likes
Thank you for the help. That worked great!
Thanks, Hideaki, that is very helpful! But what about if the rows aren’t exact duplicates? I have merged data from two dataframes and have duplicated some of the data. I want to get rid of rows with duplicate timecode, even though in some cases other data in the rows are not exact duplicates. I tried grouping by timecode then running the ‘distinct’ command but that did not work. Ideas?